Vincent BeharOn the importance of Continuous Integration for GitOpsContinuous Integration is now a common practice in software engineering. But not yet in the more recent field of “GitOps”. Let’s see why…Aug 2, 2021Aug 2, 2021
Vincent BeharIntroducing Octopilot: a CLI to automate the creation of GitHub pull request in your gitops…Gitops is often defined as “operations by pull request”. But how do you create these pull requests? With Octopilot!Jul 26, 2021Jul 26, 2021
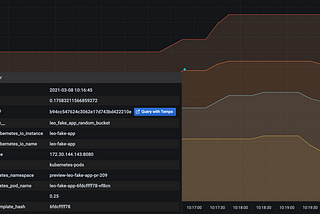
Vincent BeharUsing Prometheus Exemplars to jump from metrics to traces in GrafanaA step-by-step guide to enable correlation between metrics and traces, using Prometheus, Grafana, Tempo, OpenTelemetry, and OpenMetrics.Mar 8, 2021Mar 8, 2021
Vincent BeharinJenkins XDesigning Cloud-Native CI/CD Pipelines with Jenkins XDesign and implementation of Cloud-Native CI/CD Pipelines on Kubernetes for the enterprise, using Jenkins X.Apr 8, 2020Apr 8, 2020
Vincent BeharinDailymotionOne year with Jenkins XOne year ago, we wrote about our journey from Jenkins to Jenkins X. It’s time to take a step back and see where we are now…Mar 3, 20201Mar 3, 20201
Vincent BeharHow to protect a Kubernetes Ingress behind Okta, with NginxIn this blog post, we’ll see how easy it is to “protect” a web app behind Okta, using Nginx as a reverse-proxy in front of it. In a…Mar 3, 20202Mar 3, 20202
Vincent BeharJenkins X Pipelines Internals Part 4— StepsTechnical exploration of the Jenkins X Pipelines: how the steps — that compose a pipeline — are implemented using TektonFeb 24, 2020Feb 24, 2020
Vincent BeharJenkins X Pipelines Internals Part 3 — StagesTechnical exploration of the Jenkins X Pipelines: how the stages — that compose a pipeline — are implemented using TektonFeb 17, 2020Feb 17, 2020
Vincent BeharJenkins X Pipelines Internals Part 2 — Meta PipelineTechnical exploration of the Jenkins X Meta Pipeline — which is responsible for parsing and running the Jenkins X PipelinesFeb 6, 20201Feb 6, 20201
Vincent BeharJenkins X Pipelines InternalsThis is a series of blog posts on the internals of the Jenkins X Pipelines, implemented using Prow and Tekton.Feb 3, 20201Feb 3, 20201